Cuando trabajamos con Bases de Datos Relacionales como sistema persistente de los datos de nuestras aplicaciones, no es nada raro encontrarnos con información organizada de manera jerárquica. ¿Quién no ha trabajado alguna vez con departamentos, áreas o empleados en sus aplicaciones cuya información se encontraba persistida en una Base de Datos?
Este post pretende explicar la forma en la que podemos generar consultas SQL para obtener informaciĂłn que se encuentre estructurada de esta manera.
Nuestro punto de partida
Supongamos que tenemos la siguiente estructura jerárquica y queremos que esté almacenada en base de datos con la finalidad de poder consultarla posteriormente:
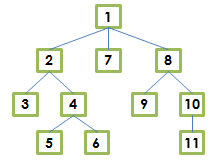
Para ello podrĂamos crear una estructura similar a esta:
DROP TABLE Node PURGE;
CREATE TABLE Node (
id NUMBER,
node_name VARCHAR2(20 BYTE),
parent_id NUMBER,
CONSTRAINT Node_pk PRIMARY KEY (id),
CONSTRAINT Node_Node_fk FOREIGN KEY (parent_id) REFERENCES Node(id)
);
CREATE INDEX Node_parent_id_idx ON Node(parent_id);
INSERT INTO Node VALUES (1, 'Nodo 1', NULL);
INSERT INTO Node VALUES (2, 'Nodo 2', 1);
INSERT INTO Node VALUES (3, 'Nodo 3', 2);
INSERT INTO Node VALUES (4, 'Nodo 4', 2);
INSERT INTO Node VALUES (5, 'Nodo 5', 4);
INSERT INTO Node VALUES (6, 'Nodo 6', 4);
INSERT INTO Node VALUES (7, 'Nodo 7', 1);
INSERT INTO Node VALUES (8, 'Nodo 8', 1);
INSERT INTO Node VALUES (9, 'Nodo 9', 8);
INSERT INTO Node VALUES (10, 'Nodo 10', 8);
INSERT INTO Node VALUES (11, 'Nodo 11', 10);
COMMIT;
COMMIT;
Consultas jerárquicas
Para poder consultar este tipo de estructuras lo primero que debemos identificar es como se relacionan los elementos hijos con sus padres. En nuestro caso todos los nodos almacenados en nuestra tabla disponen de un campo clave llamado id, y de un campo parent_id que contiene la referencia al campo id de su elemento padre.
Aunque esta relación podemos verla en la sentencia DDL que hemos visto anteriormente, Oracle dispone de una cláusula CONNECT BY que permite definir en nuestras consultas SQL cómo se relacionarán la fila actual (hijo) con la fila anterior (padre). Esta cláusula debe llevar una condición que refleje tal relación, y en dicha condición una de las expresiones debe ir cualificada con un operador llamado PRIOR definiendo asà que esa expresión se refiere a la fila del padre.
Acompañando a esta cláusula podemos utilizar otra llamada START WITH. Esta otra cláusula permite identificar mediante una condiciĂłn, que elementos son considerados raĂz de la estructura. De no utilizarla junto a CONNECT BY obtendremos más elementos de los esperados, ya que todos los nodos serán considerados como nodo raĂz y obtendremos todos los subárboles de cada uno de ellos.
AsĂ pues nuestra consulta jerárquica podrĂa ser algo similar a esto:
SELECT
id,
node_name,
parent_id
FROM
Node
START WITH parent_id IS NULL
CONNECT BY PRIOR id = parent_id;
Como vemos, en esta consulta estarĂamos indicando con START WITH que serán considerados nodos raĂces aquellos que no tienen parent_id (en nuestro caso sĂłlo el Nodo 1), y con la cláusula CONNECT BY estarĂamos diciendo que la relaciĂłn se establece entre el campo id del registro padre (cualificado con el operador PRIOR) y el campo parent_id del registro hijo.
La forma en la que ejecutarĂa esta consulta serĂa la siguiente:
- Selecciona las filas que son consideradas elementos raĂz de la estructura (evaluando la cláusula START WITH)
- Para cada fila considerada elemento raĂz, selecciona las filas que consideradas como sus hijos. Serán aquellas que satisfagan la condiciĂłn indicada en CONNECT BY con la fila raĂz que está tratando.
- Para cada fila hija recuperada, selecciona los registros considerados como sus hijos (satisfaciendo la condiciĂłn CONNECT BY pero esta vez actuando la fila actual como padre) y asĂ sucesivamente.
- Finalmente, si la consulta dispone de una clausula WHERE, aplica las condiciones que no sean consideradas condiciones de JOIN (ya que los JOIN, ya sean especificados en una cláusula FROM o en una cláusula WHERE, los realiza antes de empezar con este procesamiento)
Además Oracle incluye algunos operadores, pseudocolumnas y funciones que pueden sernos de utilidad a la hora de trabajar con estas estructuras:
- LEVEL: Esta pseudocolumna nos permite obtener el nivel de profundidad del elemento devuelto por nuestra consulta.
- CONNECT_BY_ROOT: Este operador permite cualificar columnas devueltas en nuestra consulta como campos referidos al elemento raĂz del elemento devuelto.
- SYS_CONNECT_BY_PATH: Esta funciĂłn devuelve el camino desde la raĂz al elemento devuelto. Solo puede ser utilizada como dato de salida (nunca como condiciĂłn en WHERE)
- CONNECT_BY_ISLEAF: Esta pseudocolumna indica si el elemento devuelto es una hoja o no.
- CONNECT_BY_ISCYCLE: Indica si el elemento devuelto contiene un ciclo.
- ORDER SIBLINGS BY: Aplica el orden a los nodos hermanos sin alterar la ordenaciĂłn definida a nivel de consulta
AsĂ pues podrĂamos ampliar nuestra consulta para que devuelva las descripciones del nodo padre, el identificador de la raĂz de cada elemento, el camino desde la raĂz, el nivel de profundidad del elemento devuelto o indicadores de si es hoja o tiene ciclo:
SELECT
n.id,
n.node_name,
n.parent_id,
pd.node_name parent_name,
LEVEL,
CONNECT_BY_ROOT n.id AS root_id,
LTRIM(SYS_CONNECT_BY_PATH(n.id, '-'), '-') AS path,
CONNECT_BY_ISLEAF AS leaf
FROM
Node n,
Node pd
WHERE
n.parent_id = pd.id (+)
START WITH n.parent_id IS NULL
CONNECT BY PRIOR n.id = n.parent_id
ORDER SIBLINGS BY n.id
Y obtendrĂamos algo como esto:
ID NODE_NAME PARENT_ID PARENT_NAME LEVEL ROOT_ID PATH LEAF
---- ---------- --------- ------------ ------ -------- ----------- ----
1 Nodo 1 1 1 1 0
2 Nodo 2 1 Nodo 1 2 1 1-2 0
3 Nodo 3 2 Nodo 2 3 1 1-2-3 1
4 Nodo 4 2 Nodo 2 3 1 1-2-4 0
5 Nodo 5 4 Nodo 4 4 1 1-2-4-5 1
6 Nodo 6 4 Nodo 4 4 1 1-2-4-6 1
7 Nodo 7 1 Nodo 1 2 1 1-7 1
8 Nodo 8 1 Nodo 1 2 1 1-8 0
9 Nodo 9 8 Nodo 8 3 1 1-8-9 1
10 Nodo 10 8 Nodo 8 3 1 1-8-10 0
11 Nodo 11 10 Nodo 10 4 1 1-8-10-11 1
Por último destacar que en caso de ciclos, ORACLE generará un error como este:
ORA-01436: CONNECT BY loop in user data
Si quisiĂ©ramos devolver la fila que produce el ciclo deberĂamos indicarlo en la cláusula CONNECT BY de la siguiente manera:
UPDATE Node SET parent_id = 10 WHERE id = 1;
COMMIT;
SELECT
Node.id,
Node.node_name,
Node.parent_id,
pd.node_name parent_name,
LEVEL,
CONNECT_BY_ROOT Node.id AS root_id,
LTRIM(SYS_CONNECT_BY_PATH(Node.id, '-'), '-') AS path,
CONNECT_BY_ISLEAF AS leaf,
CONNECT_BY_ISCYCLE AS cycle
FROM
Node,
Node pd
WHERE
NODE.PARENT_ID = pd.id (+)
START WITH Node.id = 1
CONNECT BY NOCYCLE PRIOR Node.id = Node.parent_id
ORDER SIBLINGS BY Node.id
En ese caso Oracle no seguirĂa las relaciones que implican el ciclo y nos devolverĂa lo siguiente:
ID NODE_NAME PARENT_ID PARENT_NAME LEVEL ROOT_ID PATH LEAF CYCLE
---- ---------- --------- ------------ ------ -------- ----------- ---- -----
1 Nodo 1 1 1 1 0 0
2 Nodo 2 1 Nodo 1 2 1 1-2 0 0
3 Nodo 3 2 Nodo 2 3 1 1-2-3 1 0
4 Nodo 4 2 Nodo 2 3 1 1-2-4 0 0
5 Nodo 5 4 Nodo 4 4 1 1-2-4-5 1 0
6 Nodo 6 4 Nodo 4 4 1 1-2-4-6 1 0
7 Nodo 7 1 Nodo 1 2 1 1-7 1 0
8 Nodo 8 1 Nodo 1 2 1 1-8 0 0
9 Nodo 9 8 Nodo 8 3 1 1-8-9 1 0
10 Nodo 10 8 Nodo 8 3 1 1-8-10 0 1
11 Nodo 11 10 Nodo 10 4 1 1-8-10-11 1 0
En en segundo post dedicado a las estructuras jerárquicas en Oracle introduciremos el uso de la clausula WITH.