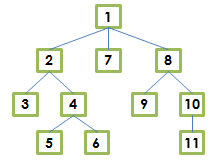
En el post anterior explicábamos la forma en la que podĂamos consultar informaciĂłn organizada de forma jerárquica en ORACLE a travĂ©s de consultas jerárquicas mediante el uso de la cláusula CONNECT BY.
En este post propondremos una alternativa mediante el uso la cláusula WITH. Su uso recursivo fue incluido en la versión 11g release 2. Por tanto este mecanismo solo es válido para las versiones de ORACLE superiores a esta.
La cláusula WITH
La cláusula WITH (también conocida como cláusula de factorización de subconsultas) fue incluida como parte del estándar SQL-99 y se añadió a la sintaxis SQL de Oracle a partir de la versión 9.2.
Para los que no la conocen, esta cláusula nos permite declarar subconsultas que pueden ser utilizadas múltiples veces en nuestras SELECTs sin necesidad de repetir su código. Estas subconsultas podrán ser procesadas como vistas “inline” o como tablas temporales según nuestras necesidades de rendimiento.