Cuando trabajamos con Bases de Datos Relacionales como sistema persistente de los datos de nuestras aplicaciones, no es nada raro encontrarnos con información organizada de manera jerárquica. ¿Quién no ha trabajado alguna vez con departamentos, áreas o empleados en sus aplicaciones cuya información se encontraba persistida en una Base de Datos?
Este post pretende explicar la forma en la que podemos generar consultas SQL para obtener informaciĂłn que se encuentre estructurada de esta manera.
Nuestro punto de partida
Supongamos que tenemos la siguiente estructura jerárquica y queremos que esté almacenada en base de datos con la finalidad de poder consultarla posteriormente:
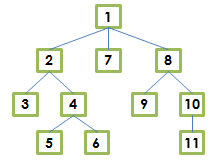
Para ello podrĂamos crear una estructura similar a esta:
DROP TABLE Node PURGE;
CREATE TABLE Node (
id NUMBER,
node_name VARCHAR2(20 BYTE),
parent_id NUMBER,
CONSTRAINT Node_pk PRIMARY KEY (id),
CONSTRAINT Node_Node_fk FOREIGN KEY (parent_id) REFERENCES Node(id)
);
CREATE INDEX Node_parent_id_idx ON Node(parent_id);
INSERT INTO Node VALUES (1, 'Nodo 1', NULL);
INSERT INTO Node VALUES (2, 'Nodo 2', 1);
INSERT INTO Node VALUES (3, 'Nodo 3', 2);
INSERT INTO Node VALUES (4, 'Nodo 4', 2);
INSERT INTO Node VALUES (5, 'Nodo 5', 4);
INSERT INTO Node VALUES (6, 'Nodo 6', 4);
INSERT INTO Node VALUES (7, 'Nodo 7', 1);
INSERT INTO Node VALUES (8, 'Nodo 8', 1);
INSERT INTO Node VALUES (9, 'Nodo 9', 8);
INSERT INTO Node VALUES (10, 'Nodo 10', 8);
INSERT INTO Node VALUES (11, 'Nodo 11', 10);
COMMIT;
COMMIT;
Consultas jerárquicas
Para poder consultar este tipo de estructuras lo primero que debemos identificar es como se relacionan los elementos hijos con sus padres. En nuestro caso todos los nodos almacenados en nuestra tabla disponen de un campo clave llamado id, y de un campo parent_id que contiene la referencia al campo id de su elemento padre.
Seguir leyendo…