En el post anterior explicábamos la forma en la que podĂamos consultar informaciĂłn organizada de forma jerárquica en ORACLE a travĂ©s de consultas jerárquicas mediante el uso de la cláusula CONNECT BY.
En este post propondremos una alternativa mediante el uso la cláusula WITH. Su uso recursivo fue incluido en la versión 11g release 2. Por tanto este mecanismo solo es válido para las versiones de ORACLE superiores a esta.
La cláusula WITH
La cláusula WITH (también conocida como cláusula de factorización de subconsultas) fue incluida como parte del estándar SQL-99 y se añadió a la sintaxis SQL de Oracle a partir de la versión 9.2.
Para los que no la conocen, esta cláusula nos permite declarar subconsultas que pueden ser utilizadas múltiples veces en nuestras SELECTs sin necesidad de repetir su código. Estas subconsultas podrán ser procesadas como vistas “inline” o como tablas temporales según nuestras necesidades de rendimiento.
Partamos del famoso esquema SCOTT con empleados y departamentos. Supongamos que queremos obtener cuanta gente trabaja su departamento. Usando una subconsulta podrĂamos tener algo similar a esto:
SELECT
e.ename AS emp_name,
dc.dept_count AS emp_dept_count
FROM
emp e,
(
SELECT deptno, COUNT(*) AS dept_count
FROM emp
GROUP BY deptno
) dc
WHERE
e.deptno = dc.deptno;
Utilizando la cláusula WITH tendrĂamos algo como esto…
WITH dept_count AS (
SELECT
deptno,
COUNT(*) AS dept_count
FROM
emp
GROUP BY deptno
)
SELECT
e.ename AS emp_name,
dc.dept_count AS emp_dept_count
FROM
emp e,
dept_count dc
WHERE
e.deptno = dc.deptno;
Como vemos, hemos dado un nombre a la subconsulta que cuenta el nĂşmero de empleados del departamento y hemos utilizado ese nombre en nuestra consulta.
Este ejemplo no parece que ofrezca mejoras significativas pero supongamos ahora que queremos mostrar además el nombre de su encargado junto con el número de empleados del departamento en el que trabaje.
La consulta podrĂa quedar asĂ:
WITH dept_count AS (
SELECT
deptno,
COUNT(*) AS dept_count
FROM
emp
GROUP BY deptno
)
SELECT
e.ename AS emp_name,
dc1.dept_count AS emp_dept_count,
m.ename AS mgr_name,
dc2.dept_count AS mgr_dept_count
FROM
emp e,
dept_count dc1,
emp m,
dept_count dc2
WHERE
e.deptno = dc1.deptno
AND e.mgr = m.empno
AND m.deptno = dc2.deptno;
Como vemos el hecho de haber declarado la subconsulta en la cláusula WITH nos ha permitidio utilizar su código más de una vez sin necesidad de repetirlo.
Esta cláusula tiene muchas más utilidades (en futuros post mostraremos algún uso más) pero con esto tenemos suficiente para comprender el mecanismo que proponemos en este nuevo POST.
Nuestro punto de partida:
Supongamos que tenemos la siguiente estructura jerárquica y queremos que esté almacenada en base de datos con la finalidad de poder consultarla posteriormente:
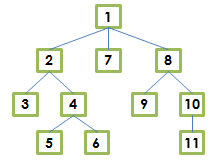
Para ello podrĂamos crear una estructura similar a esta:
DROP TABLE Node PURGE;
CREATE TABLE Node (
id NUMBER,
node_name VARCHAR2(20 BYTE),
parent_id NUMBER,
CONSTRAINT Node_pk PRIMARY KEY (id),
CONSTRAINT Node_Node_fk FOREIGN KEY (parent_id) REFERENCES Node(id)
);
CREATE INDEX Node_parent_id_idx ON Node(parent_id);
INSERT INTO Node VALUES (1, 'Nodo 1', NULL);
INSERT INTO Node VALUES (2, 'Nodo 2', 1);
INSERT INTO Node VALUES (3, 'Nodo 3', 2);
INSERT INTO Node VALUES (4, 'Nodo 4', 2);
INSERT INTO Node VALUES (5, 'Nodo 5', 4);
INSERT INTO Node VALUES (6, 'Nodo 6', 4);
INSERT INTO Node VALUES (7, 'Nodo 7', 1);
INSERT INTO Node VALUES (8, 'Nodo 8', 1);
INSERT INTO Node VALUES (9, 'Nodo 9', 8);
INSERT INTO Node VALUES (10, 'Nodo 10', 8);
INSERT INTO Node VALUES (11, 'Nodo 11', 10);
COMMIT;
Consultas jerárquicas basadas en el uso recursivo de la cláusula WITH
Como comentamos al comienzo de este post, a partir de la versión de Oracle 11g release 2, se introdujo el uso recursivo de la cláusula WITH proporcionando una alternativa al mecanismo de consultas jerárquicas del que hablamos en un post anterior.
Esta alternativa se basa en definir una subconsulta, haciendo uso de la cláusula WITH, que esté compuesta por dos bloques unidos mediante UNION ALL.
- El primer bloque de la subconsulta es el encargado de obtener la informaciĂłn de los elementos que van a actuar como raĂz de nuestra estructura jerárquica. Jamás debe hacer referencia al nombre de la consulta declarada con WITH. Es por ello que este bloque se conoce como “Ancla”.
- El segundo bloque de la subconsulta es el encargado de obtener la informaciĂłn de los hijos de nuestra estructura jerárquica. Este bloque referenciará al nombre de la consulta declarada con WITH una sola vez, consiguiendo el comportamiento recursivo necesario para navegar por la jerarquĂa. Es por ello que este bloque se conoce como “elemento recursivo”
Asà pues nuestra consulta quedará de la siguiente manera:
WITH n1(id, parent_id) AS (
-- Bloque de Ancla
SELECT
id,
parent_id
FROM
Node
WHERE
parent_id IS NULL
UNION ALL
-- Elemento recursivo
SELECT
n2.id,
n2.parent_id
FROM
Node n2,
n1
WHERE
n2.parent_id = n1.id
)
SELECT
id,
parent_id
FROM
n1;
Si ejecutásemos esta consulta obtendrĂamos el siguiente resultado:
ID PARENT_ID
---------- ----------
1
2 1
7 1
8 1
3 2
4 2
9 8
10 8
5 4
6 4
11 10
Como vemos, el árbol es recorrido devolviendo primero los nodos hermanos antes de pasar a procesar los nodos hijos (Modo de ordenación BREADTH FIRST BY).
Si quisiĂ©ramos cambiar el modo para devolver los hijos antes de procesar los nodos hermanos podrĂamos utilizar una cláusula llamada SEARCH indicando que el modo de ordenaciĂłn sea DEPTH FIRST BY.
WITH n1(id, parent_id) AS (
-- Bloque de Ancla
SELECT
id,
parent_id
FROM
Node
WHERE
parent_id IS NULL
UNION ALL
-- Bloque recursivo
SELECT
n2.id,
n2.parent_id
FROM
Node n2,
n1
WHERE
n2.parent_id = n1.id
)
SEARCH DEPTH FIRST BY id SET myOrder
SELECT
id,
parent_id
FROM
n1
order by myOrder;
El resultado que obtendrĂamos en este caso es:
ID PARENT_ID
---------- ----------
1
2 1
3 2
4 2
5 4
6 4
7 1
8 1
9 8
10 8
11 10
Algo que puede sernos de utilidad es calcular el camino completo hasta el elemento de la jerarquĂa. La forma de hacerlo serĂa la siguiente:
WITH n1(id, parent_id, path) AS (
-- Bloque de Ancla
SELECT
id,
parent_id,
TO_CHAR(id) AS path
FROM
Node
WHERE
parent_id IS NULL
UNION ALL
-- Bloque recursivo
SELECT
n2.id,
n2.parent_id,
n1.path || '-' || n2.id AS path
FROM
Node n2,
n1
WHERE
n2.parent_id = n1.id
)
SEARCH DEPTH FIRST BY id SET myOrder
SELECT
id,
parent_id,
path
FROM
n1
order by myOrder;
Como vemos lo Ăşnico que tenemos que hacer es declararlo como columna de salida de nuestra subconsulta factorizable y utilizarla en el bloque recursivo.
En este caso obtendrĂamos algo como esto:
ID PARENT_ID PATH
---------- ---------- ----------
1 1
2 1 1-2
3 2 1-2-3
4 2 1-2-4
5 4 1-2-4-5
6 4 1-2-4-6
7 1 1-7
8 1 1-8
9 8 1-8-9
10 8 1-8-10
11 10 1-8-10-11
PodrĂa darse el caso de que en nuestra estructura jerárquica existieran ciclos, es decir caminos circulares que harĂan que nuestra consulta jerárquica entrará en un bucle de llamadas recursivas.
En este caso obtendrĂamos un error similar a este:
ORA-32044: cycle detected while executing recursive WITH query
Para detener la navegación por el ciclo podemos hacer uso de la cláusula CYCLE:
UPDATE Node SET parent_id = 10 WHERE id = 1;
COMMIT;
WITH n1(id, parent_id, path) AS (
-- Bloque de Ancla
SELECT
id,
parent_id,
TO_CHAR(id) AS path
FROM
Node
WHERE
id = 1
UNION ALL
-- Bloque recursivo
SELECT
n2.id,
n2.parent_id,
n1.path || '-' || n2.id AS path
FROM
Node n2,
n1
WHERE
n2.parent_id = n1.id
)
SEARCH DEPTH FIRST BY id SET myOrder
CYCLE id SET iscycle TO 1 DEFAULT 0
SELECT
id,
parent_id,
path,
iscycle
FROM
n1
order by myOrder;
Lo que indicamos con dicha cláusula es que sea considerado un ciclo cuando el campo id de un nodo es el mismo que el de cualquier nodo situado por encima de él. En este caso se crea una variable a nivel de registro llamada iscycle que tendrá valor 1 en caso de ser el causante del ciclo o un 0 en caso contrario.
AsĂ pues, podrĂamos ampliar nuestra consulta para obtener otra informaciĂłn como el nombre del elemento padre, el identificador de la raĂz, el path desde la raĂz, el nivel de profundidad…
WITH n1(id, node_name, parent_id, parent_name, "level", root_id, path) AS (
-- Bloque de Ancla
SELECT
n.id, n.node_name, n.parent_id, p.node_name as parent_name,
1 as "level", n.id as root_id, to_char(n.id) as path
FROM
Node n,
Node p
WHERE
n.parent_id = p.id (+)
AND n.parent_id IS NULL
UNION ALL
-- Bloque recursivo
SELECT
n2.id, n2.node_name, n2.parent_id, p2.node_name as parent_name,
"level" + 1 as "level", root_id, n1.path || '-' || n2.id as path
FROM
Node n2,
Node p2,
n1
WHERE
n2.parent_id = p2.id (+)
AND n2.parent_id = n1.id
)
SEARCH DEPTH FIRST BY id SET order1
CYCLE id SET "cycle" TO 1 DEFAULT 0
SELECT
id,
node_name,
parent_id,
parent_name,
"level",
root_id,
path,
"cycle"
FROM
n1
order by order1
Esperamos que esta pequeña aportación os haya sido de ayuda.